|
Just made this revision poster to give to my year 11's at parents eveing tomorrow! Big thanks to @Corbettmaths and @Hegartymaths for making such fantastic videos! These QR codes are going to form our 'Coundown to the exam' process, there is just enough that students have 5 topics per week to scan and revise in the evening! Hope someone finds it useful! I'll be opening the new 'Revision Page' on saturday when I have some time to upload a few more resources onto the page, this will be available to download there but if you can't wait here it is: Download QR Poster 
7 Comments
So after the last post on feedback I recieved a few messages asking about how I was using the feedback sheets in lessons and how I was using them for KS4 so here it is. Part of my focus this year has been developing this process, and there are still some small aspects that I beleive need ironing out but it is currently maneageable and effective which has been my aim from the start. The main thing that I am doing now to gauge what feedback I give is using topic assessments every 2 weeks. The examples shown below are after a 2 week stretch on simultanous equations with a high achieving KS4 set, at the time of the assessment we had covered algebraic linear and quadratic simultaneous equations and done a small amount on graphical linear simultaneous equations. The only feedback I give now is on these assessments, after all if a student gets 20 questions wrong in their books on a particular subtopic and this has helped lead to mastery when completing the assessments, why bother marking all those mistakes when everything is self assessed in class time and they now understand it as proven by the assessment? I am strongly of the opinion that these periods of self assessment are incredibly powerful and I insist that all work must be marked and corrected in class so that I can conduct my AFL during classtime.
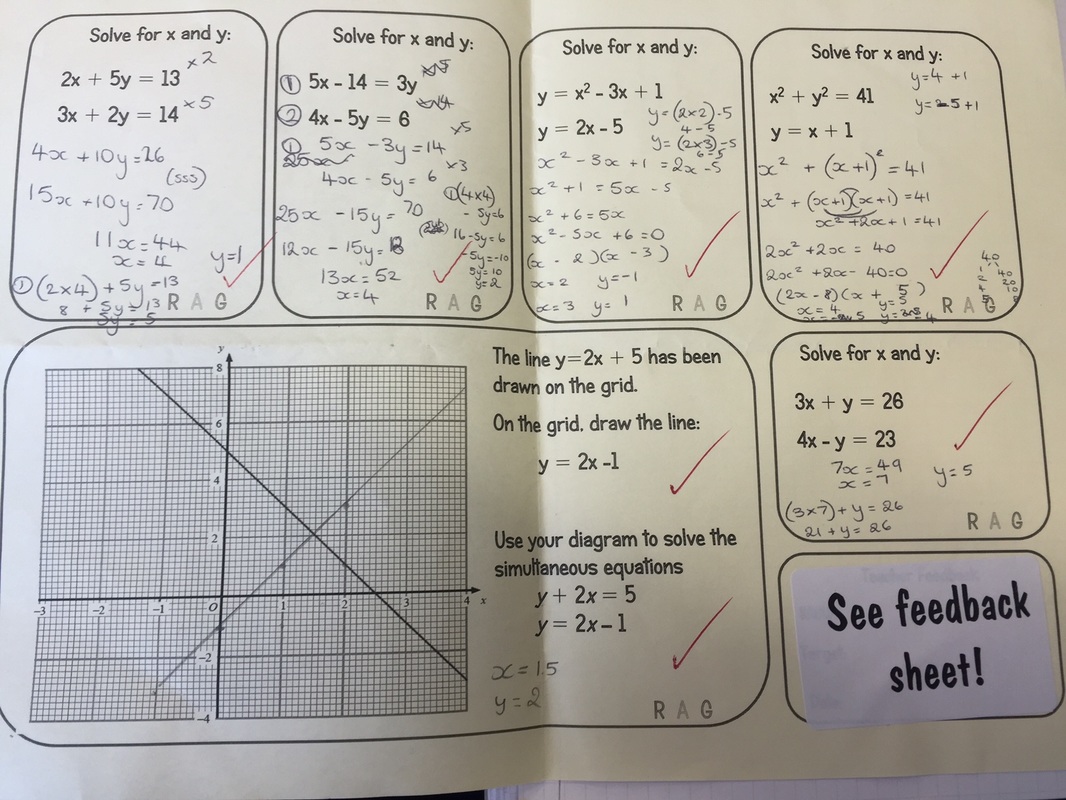 After the class has done the assessment I get these marked and fedback on for the next upcoming lesson, this particular set took me 1 hour and 33 minutes (I was asked to time it by a member of the department, so no.. I am not that sad), it took me slightly longer than usual as some of the methods and feedback elements were slightly more complex than basic fractions with year 7. Again each memeber of the class recieved written feedback on their own relevent sheet, some had algebraic linear equations, some quadratic focussing on either the 'y=' method or the substitution method when using the equation of a circle, and others had graphical simultaneous equations. So feedback responses were all being targeted at indivudual areas for improvement.
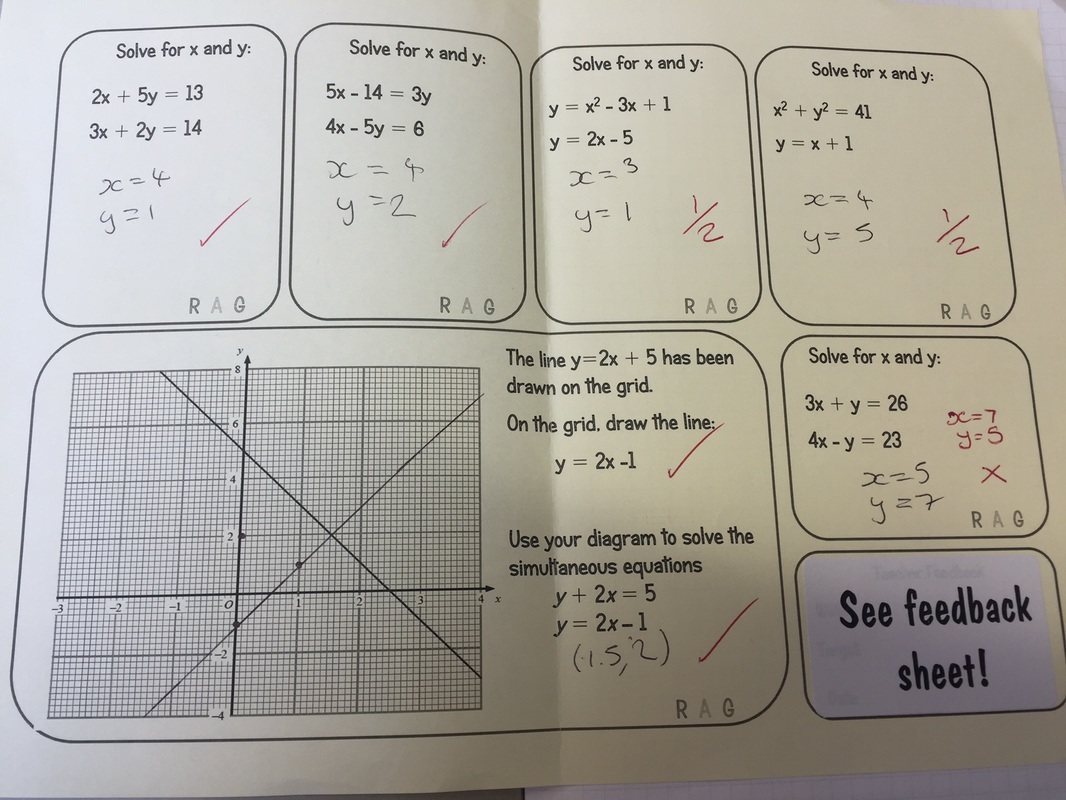
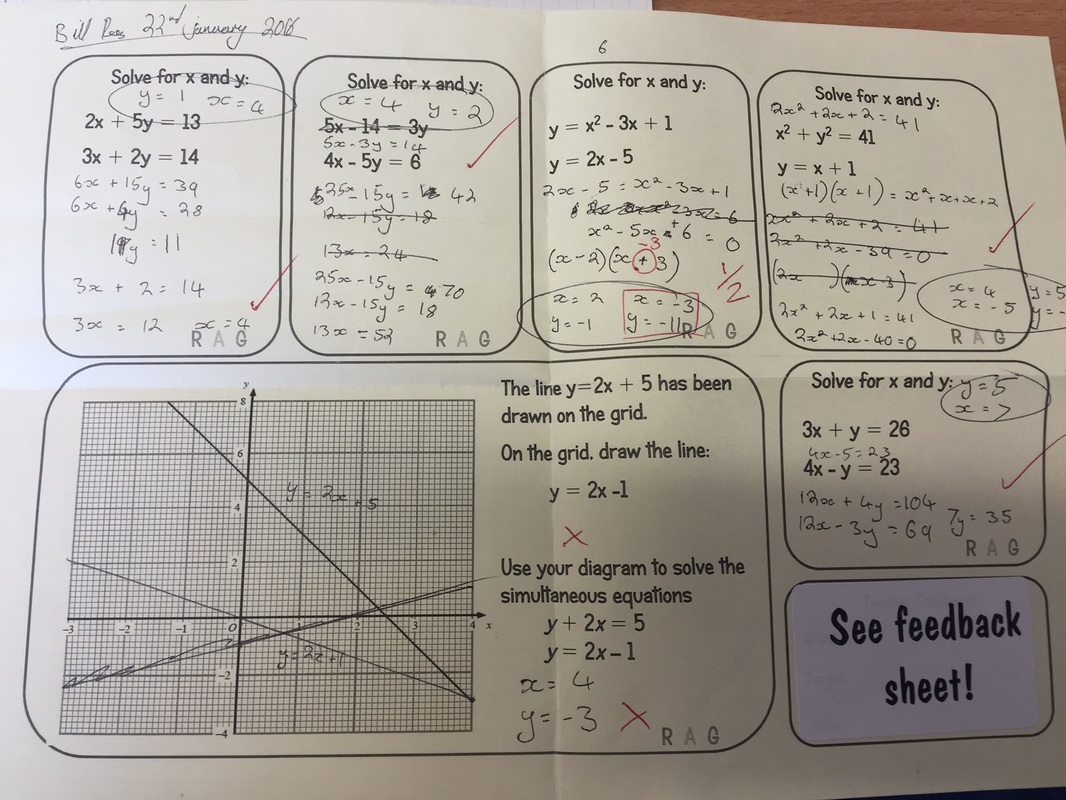
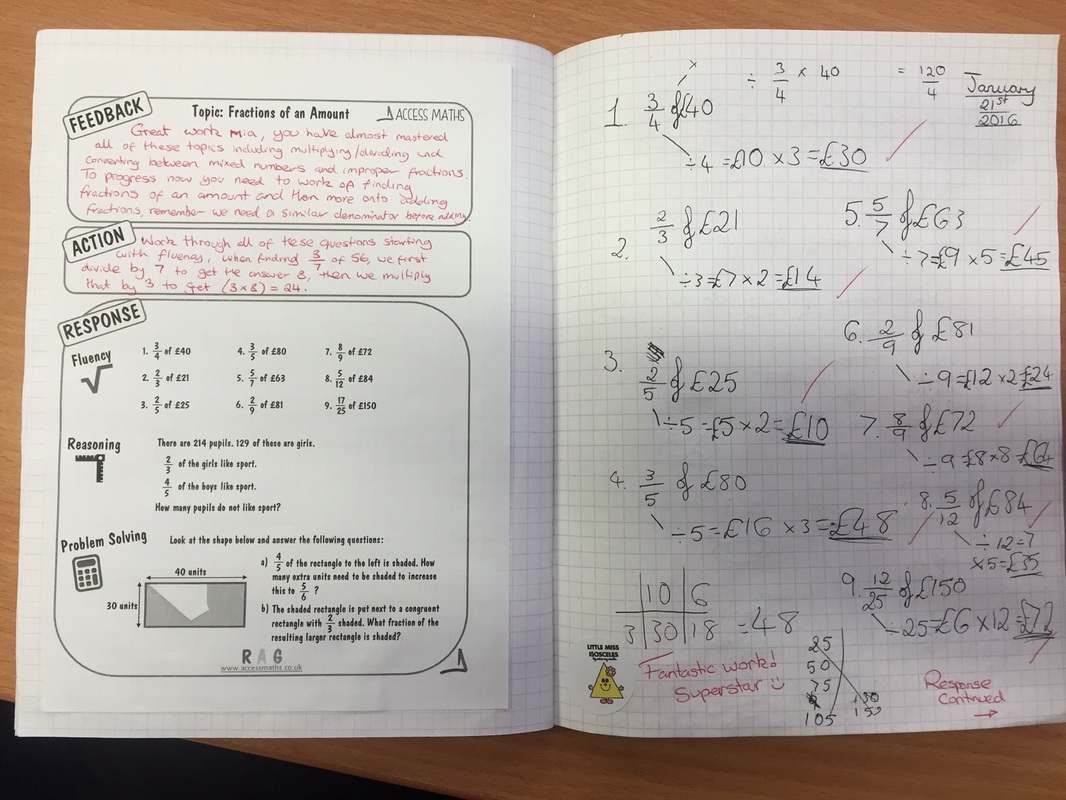
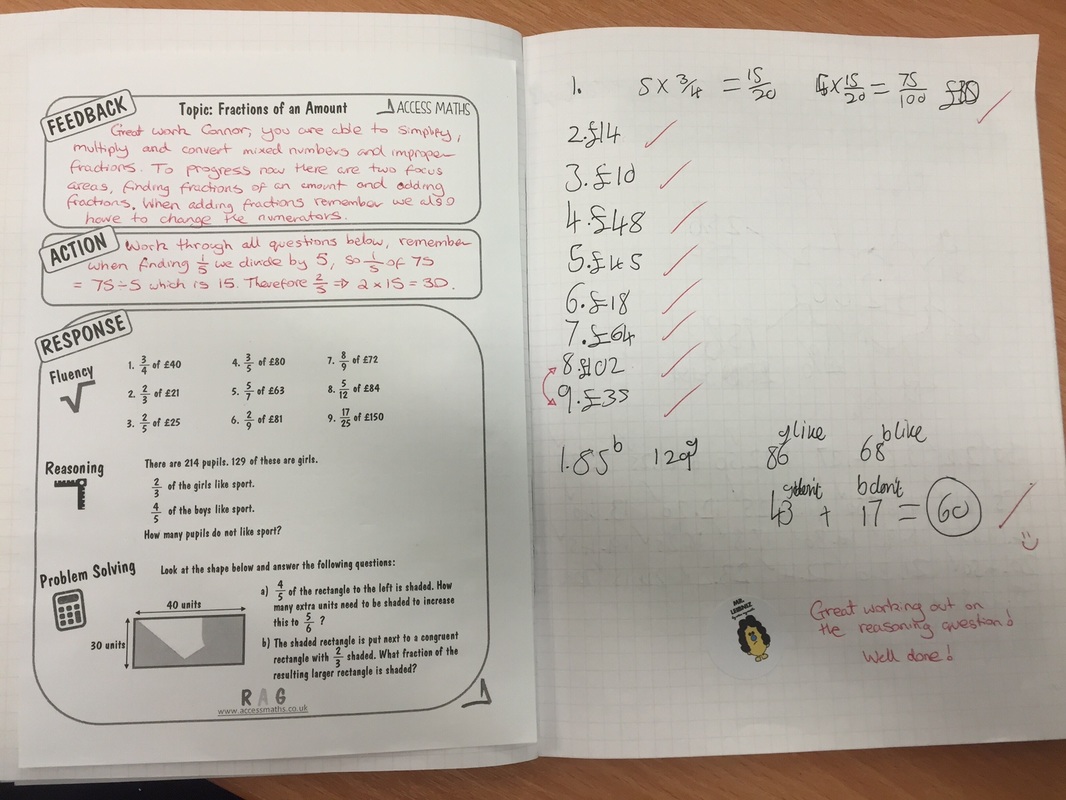
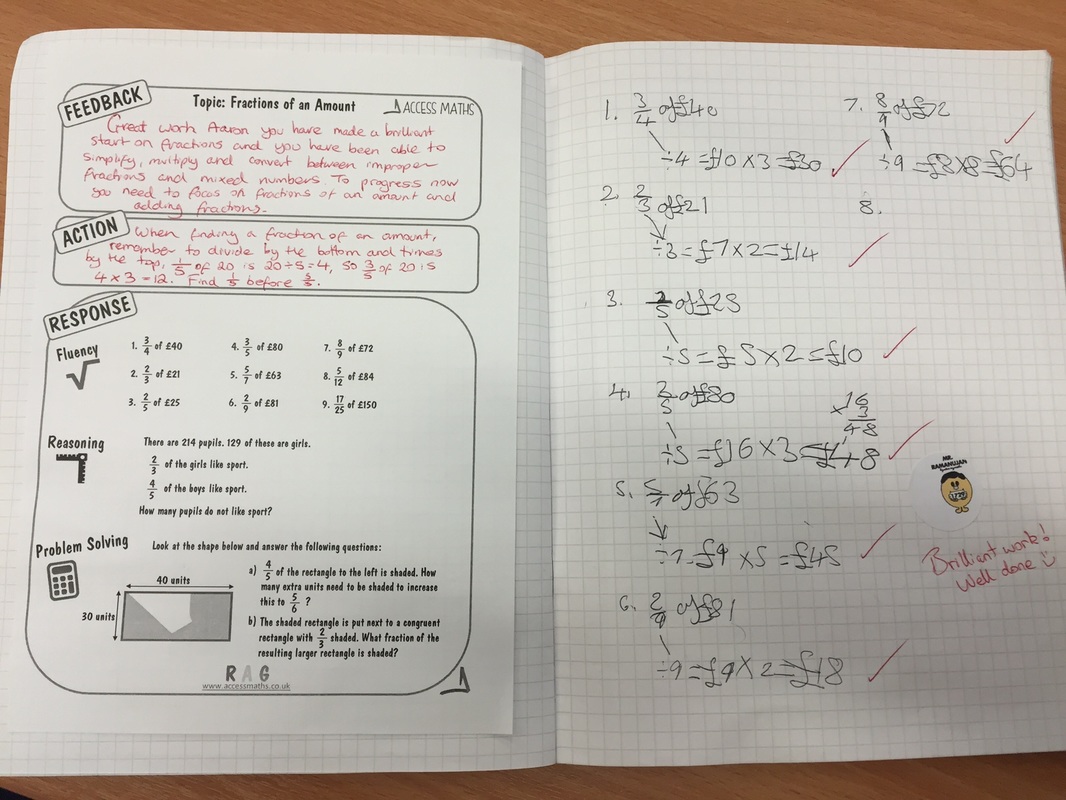
Once completed, the next lesson students have around 30 minutes to read through the feedback and complete the relevent rosponse areas, students have questions to work through focusing on fluency, reasoning and problem for each topic. Along with this, each feedback sheet has it's own relevent 'help sheet' that you can see in the pictures below. One thing I found was that giving 32 students a bunch of questions on a topic they couldn't do on the assessment was a recipe for a riot of 'I don't get it', as it was impossible to provide extended feedback for 6 different sub topics beyond the written element in order for them to make a confident start on the questions. If needed students can collect the relevent help sheet and start working straight away. I have found this particularly useful for some of my classes that I have focussed on building resilience, students are now directing themselves towards 'revision material' or 'help sheets' rather than relying on me. Some example pictures shown below: 
So far this system has been working well, I have run it across all of my year groups a few times now and the quality of the responses has improved tremendously. Students have been more engaged within the lesson and are becoming more and more motivated to improve upon areas they need to develop. One student read their feedback the lesson after the DIRT session last week and said "Sir this has made my week, thank you!". Atleast I know it's being appreciated by some one. 9-1 Feedback Sheets
It's not really something I am fond on putting my marking out into the public domain, so I'll start it off straight away with the reason I feel uncomfortable to do so. I know that my marking isn't yet perfect, although I do beleive I am doing my best at this point in time. I have been constantly re-assessing my feedback this year and refining the way I approach it, earlier in August I had just over 100 students fill in a questionnaire asking them what they thought of the feedback they received in mathematics, and asked them to write in some qualitative feedback. This was actually really useful, and I would definitely recommend trying it out. Ultimately, this has helped lead to where I currently am with my own feedback this new term. As teachers, marking is quite personal, especially if you have spent hours doing it! So having others pass judgement on it is always going to be a tough conversation (if the conversations isn't a positive one anyway).
So first of all, all of my marking tends to take place in class, ALL classwork is marked by students in green pen, there is rarely a task that we ever do in class that we don't get instant feedback on and self assessed in class. I find that it very quickly allows me to undertake my AFL around the room when you can see ticks or crosses very clearly in the students books. So the only part that I actually onduct a detailed mark on is end of topic assessments and teacher assessed homeworks, then finally on student responses to feedback. Fortunately these tend to fall every 12-14 days which falls in line with the schools marking policy of two weeks. Below is a typical topic assessment, this is with a 'bottom set' year 7 class I teach 3 times a week.
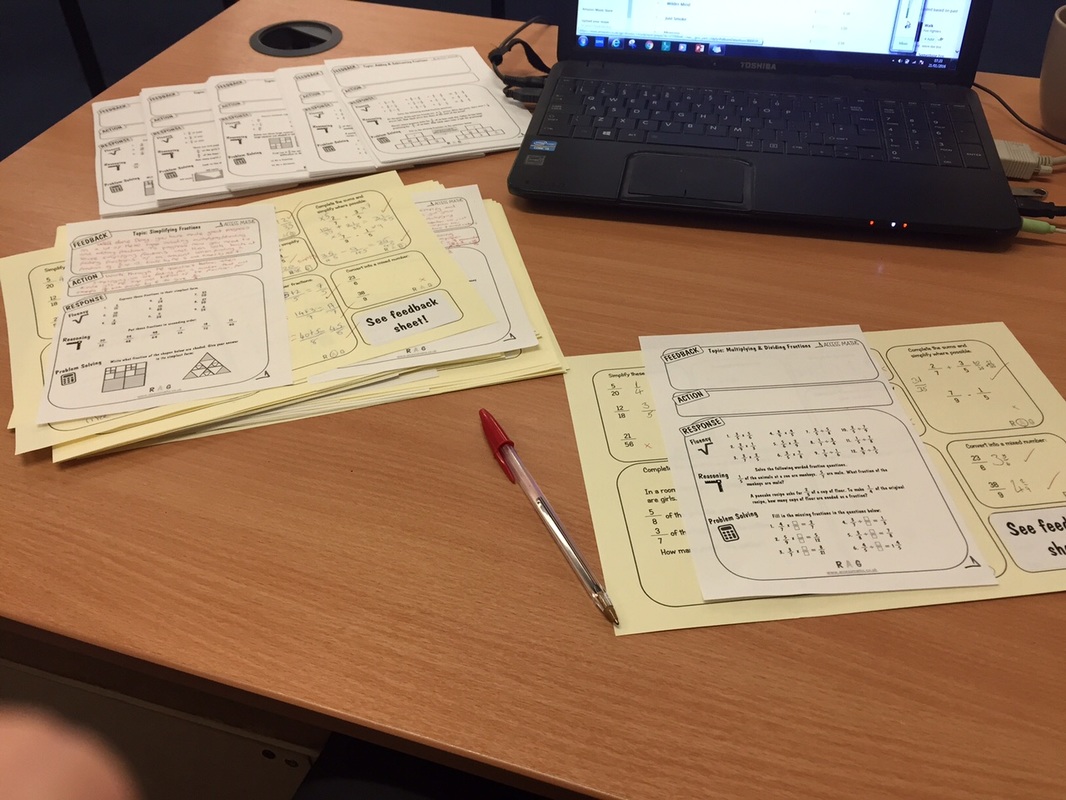
While marking the assessments I have (for this particular assessment) 5 different feedback sheets in front of me; simplifying fractions, finding fractions of an amount, multiplying/dividing fractions, adding/subtracting fractions, and converting improper fractions and mixed numbers. As I am marking the assessment, I then pick up the sheet which each student needs to improve on and provide their feedback on this particular sheet. At the start of the next lesson students then stick these sheets in on a double page spread and work on their responses on the opposite page. What I had found previously was that writing in a question was taking me an extra few minutes per book, and then once in class it was extremely difficult to ensure that all students had completed that question as one student would finish in a few minutes where as others would need much longer. This is why I have put these new sheets together, it gives students time to consolidate, challenge and extend the topic they struggled on and allows them to work through reasoning and problem solving style questions in line with the new GCSE. Some examples of books from this year 7 class are shown below:
So far, after around 9-10 DIRT sessions this term across all my classes, students have been really engaged in these feedback sessions, there is enough work to be getting on with that it allows me to get around the class and provide verbal feedback to those who struggled more than others on particular topics, while those who are happy to work through the whole sheet can move onto all levels of questions and get some challenge on the problem solving questions. I have been dedicating around 30 minutes of a lesson to these DIRT sessions so far and have found this is just enough time that everyone will be able to complete the 'fluency' questions while others are completing all levels of questions. The only written feedback I am now giving is on the 9-1 Feedback Sheets I have been uploading. It's taking me on average 1 hour to mark a set of 30 mini assessments and provide feedback and actions for each student. And this is happening after every topic or series of subtopics, for example my year 9's have been doing algebraic fractions and we have recently done an assessment on simplifying them. Students then had to work on either factorising quadratics, simplifying basic algebraic fractions or simplifying algebraic fractions involving quadratics. See example image below:  Anyway that's what I'm doing! If you have been using these in a different way or have any ideas then please let me know! You can access all of these sheets on the link below: 9-1 Feedback Sheets

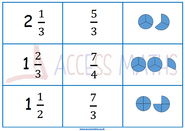
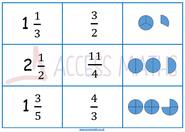
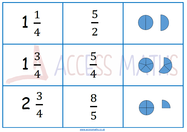
Made some new resources! Last week I made the fatal mistake of assuming prior knowledge with a class I am covering once a week. We were set to do multiplying fractions and I mistakedly assumed they would have prior knowledge of improper fractions and mixed numbers.. big mistake! Anyway, quickly remedied the situation and decided I would make sure the one lesson we have together counts so I've put together a worksheet and match cards covering mixed numbers and improper fractions. The match cards will be used first, I have put in the visual alongside the improper fraction and finally the mixed number. Pictures below:
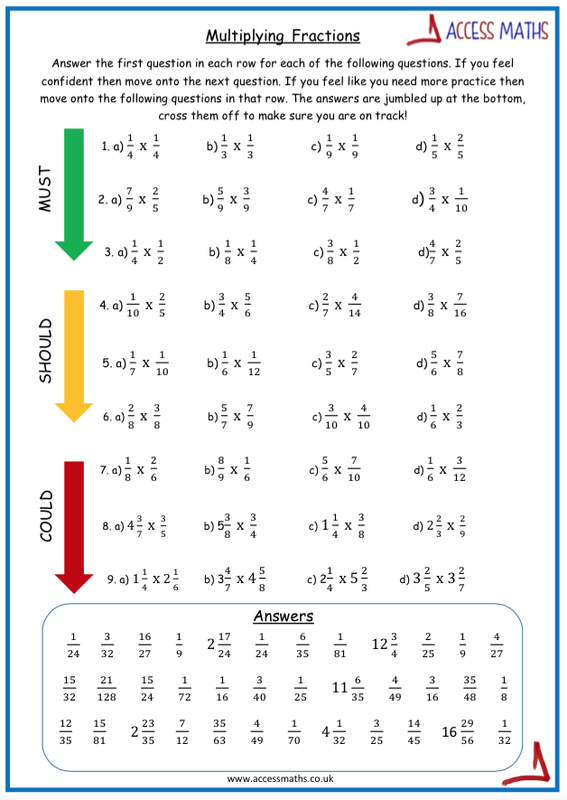
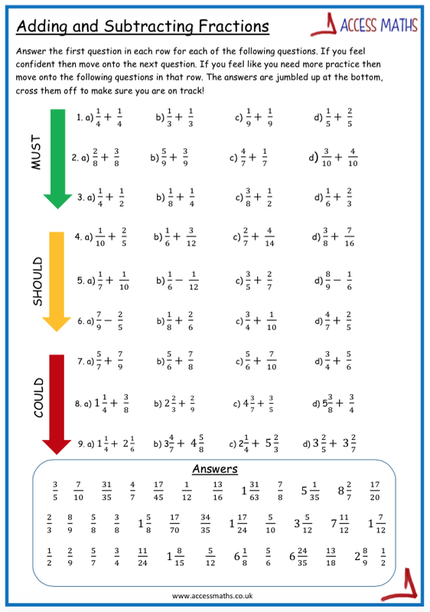
Final task for the lesson I've put together a worksheet using the 'Got it, Smashed it, Mastered it' theme. First section looking at the visual building on from the match card activity. Final sections then ask students to convert between improper fractions and mixed numbers. A few extension questions thrown in there also for good measure!  Feels like all I am doing is data at the moment as I have data with 3 different classes! Decided I needed to make some new resources to mix it up a bit! Here's the first one, some box plots match cards. Students have to match the box plot to the data and then also to the interquartile range calculation. I am going to use it as an introduction with my KS3 class before we start building them. Hope you find these useful I hope there are no mistakes! I am only human though so please do let me know if there are! :-) You can download the full box plots file here Here is a picture of one of the sheets. I have also done a blank template to be used as an extension which you can get here 
Lift off on vector collector! I have to be honest I am sick of looking at these graphics now, I think this may be the last one in the co-ordinate grid series of games! I am going to move onto something different for the next one so any suggestions will be welcome! I'm pretty happy with this one though I was't sure it was going to work! :-)  Again this game is for one or two players, the aim is to use vectors to move around the board collecting different points based on gold, silver or bronze nuggets. The player moves in the x-direction first and then in the y-direction. As it stands there are unlimited moves at the moment. Simply to give the player enough chance to play and understand the use of vectors before the game ends. I may be making some changes to this in the future though. Maybe an arcade round with time or limited rounds. Below you can see the players start at the origin.  The game can also be played in single player. As it stands the game is quite easy to play and not too much of a challenge on single player. Any suggestions are welcome though please message me via the website or on twitter @accessmaths 
Now I can't take all the credit for this one as it was created after a lengthy discussion with Mel from www.justmaths.co.uk @Just_Maths so thanks to Mel also for helping me design this :-)
I've made this worksheet so that each line progresses in difficulty. There are very slight changes moving up in the questions showing the progression of this topic. I hope you like it! :-) Students also have all the answers so there was no need for any hands up! If the answer was't there then it was wrong! (Apart from the one I got wrong that my two 'mistake hunters' found for me) You can download the fractions worksheet here Made another one of these worksheets for percentage decreases as well! Seeming as my class enjoyed the first one so much I thought I'd keep it going. The worksheet is exactly the same as the percentage increases one except they are all decreases. There are some extension question on there as well and the final extension in the mastered section should stretch those that reach it. I hope you like this one! Hopefully I will get a few made over the half term! You can download this percentage decrease worksheet here You can also download the answer sheet here if you want it.  |
Search for a topic
Categories
All
Archives
May 2018
|















 RSS Feed
RSS Feed
|
Maths Resources @AccessMaths
|
©AccessMaths 2015
|